拆包包游戏源码2022(源码解读)
▌写在前面:
大家好,我是大吴号,在前面的文章中,尼恩已经再一次的进行了通讯协议的重新选择
这就是:放弃了大家非常熟悉的json 格式,选择了性能更佳的 protobuf协议
在上一篇文章中,并且完成了netty 和 protobuf协议整合实战
具体的文章为: netty+protobuf 整合一:实战案例,带源码
另外,专门开出一篇文章,介绍了通讯消息数据包的几条设计准则
具体的文章为: netty +protobuf 整合二:protobuf 消息通讯协议设计的几个准则
在开始聊天器实战开发之前,还有一个非常基础的问题,需要解决:
这就是通讯的粘包和半包问题
注:本文以 pdf 持续更新,最新尼恩 架构笔记、面试题 的pdf文件,请到《技术自由圈》公众号获取
▌什么是粘包和半包?
先从数据包的发送和接收开始讲起
发送一次数据,举例如下:
channel.writeandflush(buffer);读取一次数据,举例如下:
public void channelread(channelhandlercontext ctx, object msg){ bytebuf bytebuf = (bytebuf) msg; //....}我们的理想是:发送端每发送一个buffer,接收端就能接收到一个一模一样的buffer
然而,理想很丰满,现实很骨感
在实际的通讯过程中,并没有大家预料的那么完美
一种意料之外的情况,如期而至这就是粘包和半包
那么,什么是粘包和半包?
粘包和半包定义如下:
▌粘包和半包 图解:
上面的理论比较抽象,下面用一幅图来形象说明
下图中,发送端发出4个数据包,接受端也接受到了4个数据包但是,通讯过程中,接收端出现了 粘包和半包
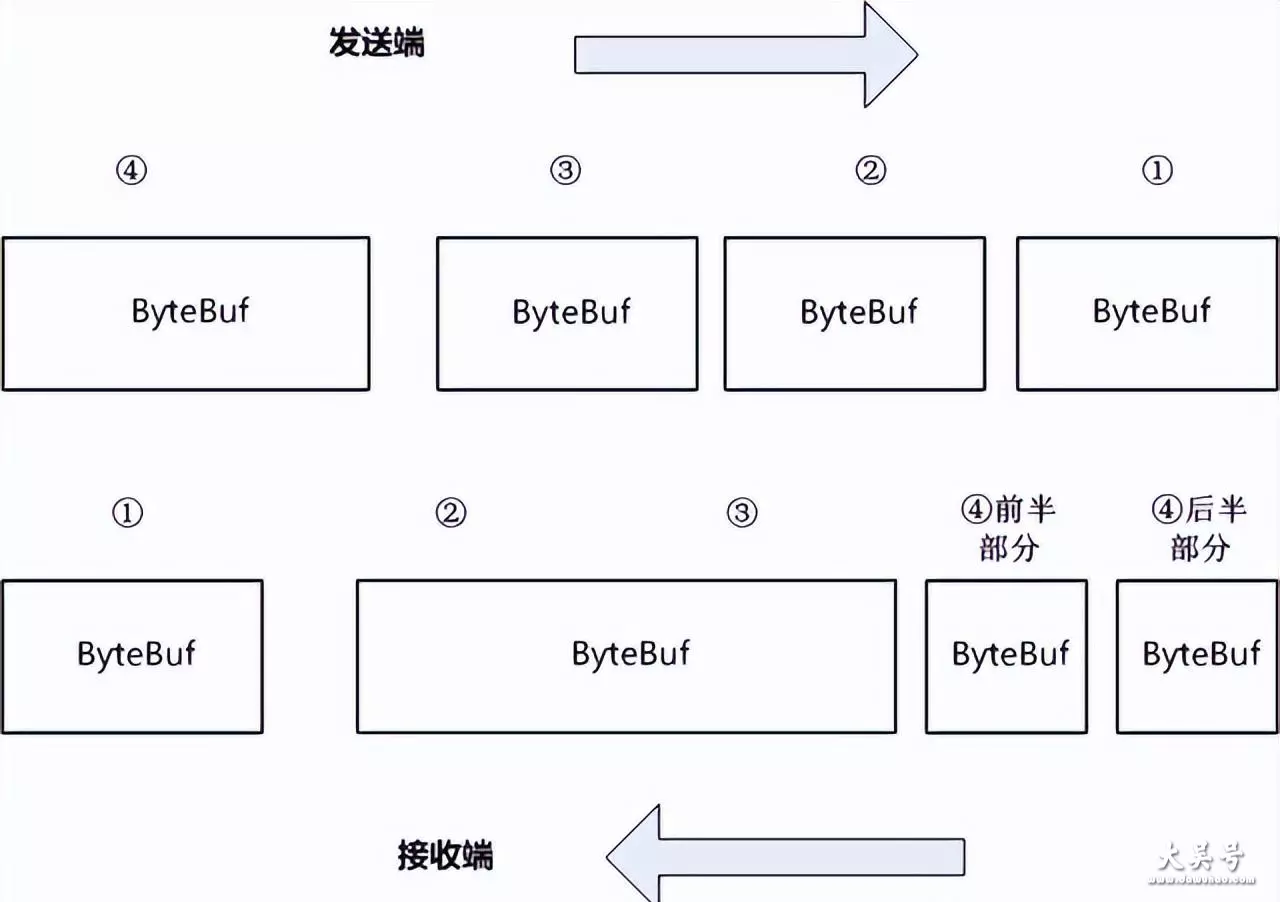
接收端收到的第一个包,正常
接收端收到的第二个包,就是一个粘包 将发送端的第二个包、第三个包,粘在一起了
接收端收到的第三个包,第四个包,就是半包将发送端的的第四个包,分开成了两个了
▌半包的实验:
由于在前文 netty+protobuf 整合一:实战案例,带源码 的源码中,没有看到异常的现象是因为代码屏蔽了半包的输出,所以看到的都是正常的数据包
稍微调整一下,在前文解码器的代码,加上半包的提示信息输出,就可以看到半包的提示
示意图如下:
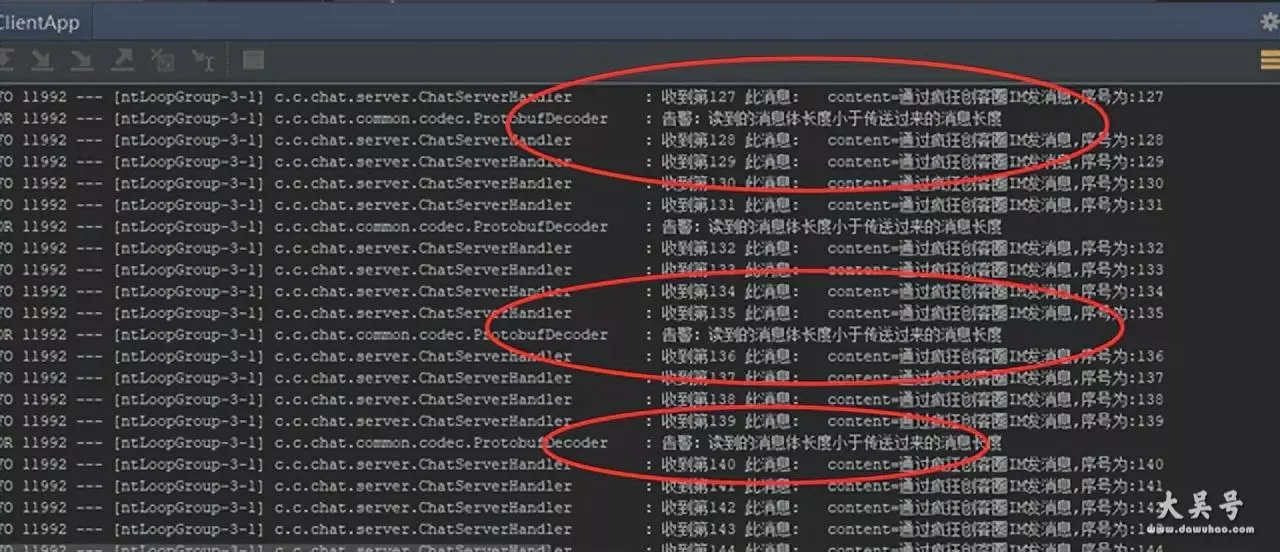
调整过的半包警告的代码,如下:
/** * 解码器 * */public class protobufdecoder extends bytetomessagedecoder { //.... protected void decode(channelhandlercontext ctx, bytebuf in, listobject out) throws exception { //... // 读取传送过来的消息的长度 int length = in.readunsignedshort(); //... if (length in.readablebytes()) { // 读到的半包 // ... log.error("告警:读到的消息体长度小于传送过来的消息长度"); return; } //... 省略了正常包的处理 }}具体的源码,请参见本文末的源码工程:netty 粘包/半包原理与拆包实战 源码
可以根据文末源码,进行实验
▌粘包和半包更全实验:
上面的实例,只能看到半包的结果,看不到粘包的结果
为了看到粘包的场景,这里,不使用protobuf 协议,直接使用缓冲区进行读写通讯,设计了一个的简单的演示实验案例
案例已经设计好,可以根据文末源码,进行实验
运行实例,不仅可以看到半包的提示信息输出,而且可以看到粘包的提示信息输出,示意图如下:
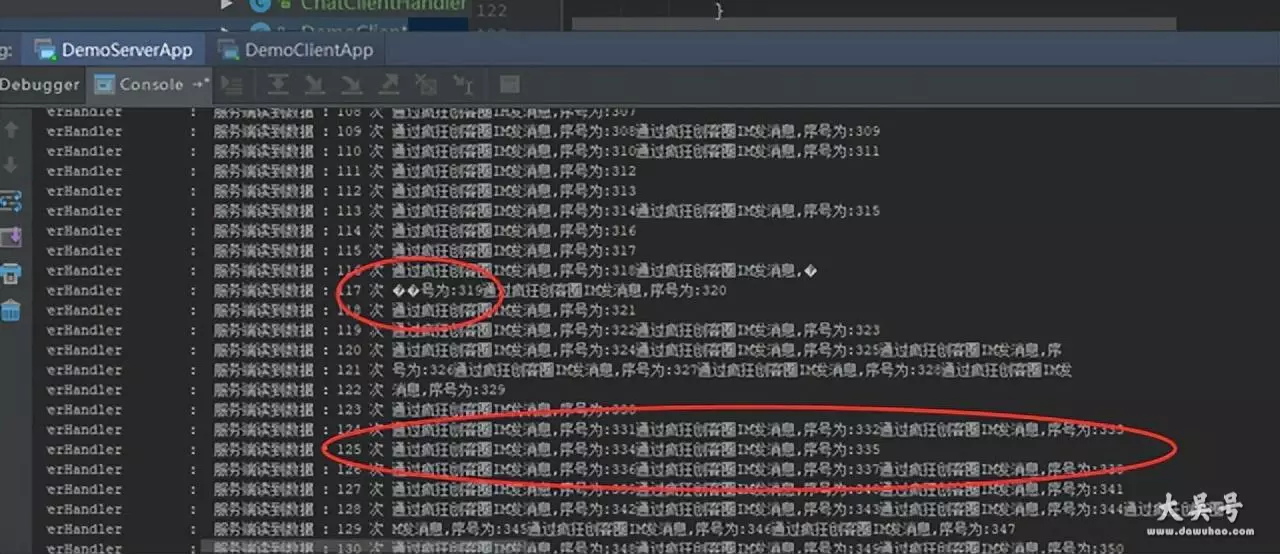
我们可以看到,服务器收到的数据包,有包含多个发送端数据包的,这就是粘包了
另外,接收端还有出现乱码的数据包,就是只包含部分发送端数据,这就是半包了
这个实例的源码,直接简化了前面的基于protobuf协议通讯的实例源码代码的逻辑结构,是一样的
本实验的具体的源码,还是请参见本文末的源码工程:netty 粘包/半包原理与拆包实战 源码
▌粘包和半包原理:
这得从底层说起
在操作系统层面来说,我们使用了 tcp 协议
这就是粘包和半包的根源
首先,上层应用层每次读取底层缓冲的数据容量是有限制的,当tcp底层缓冲数据包比较大时,将被分成多次读取,造成断包,在应用层来说,就是半包
其次,如果上层应用层一次读到多个底层缓冲数据包,就是粘包
如何解决呢?
基本思路是,在接收端,需要根据自定义协议来,来读取底层的数据包,重新组装我们应用层的数据包,这个过程通常在接收端称为拆包
▌拆包的原理:
拆包基本原理,简单来说:
- 接收端应用层不断从底层的tcp 缓冲区中读取数据
- 每次读取完,判断一下是否为一个完整的应用层数据包如果是,上层应用层数据包读取完成
- 如果不是,那就保留该数据在应用层缓冲区,然后继续从 tcp 缓冲区中读取,直到得到一个完整的应用层数据包为止
- 至此,半包问题得以解决
- 如果从tcp底层读到了多个应用层数据包,则将整个应用层缓冲区,拆成一个一个的独立的应用层数据包,返回给调用程序
- 至此,粘包问题得以解决
▌netty 中的拆包器:
拆包这个工作,netty 已经为大家备好了很多不同的拆包器本着不重复发明轮子的原则,我们直接使用netty现成的拆包器
netty 中的拆包器大致如下:
- 固定长度的拆包器 fixedlengthframedecoder
每个应用层数据包的都拆分成都是固定长度的大小,比如 1024字节
这个显然不大适应在 java 聊天程序 进行实际应用
- 行拆包器 linebasedframedecoder
每个应用层数据包,都以换行符作为分隔符,进行分割拆分
这个显然不大适应在 java 聊天程序 进行实际应用
- 分隔符拆包器 delimiterbasedframedecoder
每个应用层数据包,都通过自定义的分隔符,进行分割拆分
这个版本,是linebasedframedecoder 的通用版本,本质上是一样的
这个显然不大适应在 java 聊天程序 进行实际应用
- 基于数据包长度的拆包器 lengthfieldbasedframedecoder
将应用层数据包的长度,作为接收端应用层数据包的拆分依据按照应用层数据包的大小,拆包这个拆包器,有一个要求,就是应用层协议中包含数据包的长度
这个显然比较适和在 java 聊天程序 进行实际应用下面我们来应用这个拆分器
▌拆包之前的消息包装:
在使用
lengthfieldbasedframedecoder 拆包器之前 ,在发送端需要对protobuf 的消息包进行一轮包装
发送端包装的方法是:
在实际的protobuf 二进制消息包的前面,加上四个字节
前两个字节为版本号,后两个字节为实际发送的 protobuf 的消息长度

强调一下,二进制消息包装,在发送端进行
修改发送端的编码器 protobufencoder ,代码如下:
/** * 编码器 */ public class protobufencoder extends messagetobyteencoderprotomsg.message {@overrideprotected void encode(channelhandlercontext ctx, protomsg.message msg, bytebuf out) throws exception{ byte bytes = msg.tobytearray();// 将对象转换为byte int length = bytes.length;// 读取 protomsg 消息的长度 bytebuf buf = unpooled.buffer(2 + length); // 先将消息协议的版本写入,也就是消息头 buf.writeshort(constants.protocol_version); // 再将 protomsg 消息的长度写入 buf.writeshort(length); // 写入 protomsg 消息的消息体 buf.writebytes(bytes); //发送 out.writebytes(buf); }}发送端的步骤是:
- 先将消息协议的版本写入,也就是消息头
buf.writeshort(constants.protocol_version);
- 再将 protomsg 消息的长度写入 buf.writeshort(length);
▌开发一个接收端的自定义拆包器:
使用netty中,基于长度域拆包器
lengthfieldbasedframedecoder,按照实际的应用层数据包长度来拆分
需要做两个工作:
- 设置长度信息(长度域)在数据包中的位置
- 设置长度信息(长度域)自身的长度,也就是占用的字节数
在前面的小节中,我们的长度信息(长度域)的占用字节数为 2个字节; 在报文中的所处的位置,长度信息(长度域)处于版本号之后
版本号是2个字节,从0开始数,长度信息(长度域)的在数据包中的位置为2
这些数据定义在constansts常量类中
public class constants{//协议版本号public static final short protocol_version = 1;//头部的长度: 版本号 + 报文长度public static final short protocol_headlength = 4;//长度的偏移public static final short length_offset = 2;//长度的字节数public static final short length_bytes_count = 2;}有了这些数据之后,可以基于netty 的长度拆包器
lengthfieldbasedframedecoder, 开发自己的长度分割器
新开发的分割器为packagespliter,代码如下:
package com.crazymakercircle.chat.common.codec;public class packagespliter extends lengthfieldbasedframedecoder{ public packagespliter() { super(integer.max_value, constants.length_offset,constants.length_bytes_count); } @override protected object decode(channelhandlercontext ctx, bytebuf in) throws exception { return super.decode(ctx, in); }}分割器 packagespliter 继承了
lengthfieldbasedframedecoder,传入了三个参数
- 长度的偏移量 ,这里是 constants.length_offset,值为 2
- 最大的应用包长度,这里是 integer.max_value,表示不限制
分割器 写好之后,只需要在 pipeline 的最前面加上这个分割器,就可以使用这个分割器(自定义的拆包器)
▌自定义拆包器的实际应用:
在服务器端的 pipeline 的最前面加上这个分割器,代码如下:
package com.crazymakercircle.chat.server;//...@service("chatserver")public class chatserver{ static final logger logger = loggerfactory.getlogger(chatserver.class);//...//有连接到达时会创建一个channelprotected void initchannel(socketchannel ch) throws exception{ //应用自定义拆包器 ch.pipeline().addlast(new packagespliter()); ch.pipeline().addlast(new protobufdecoder()); ch.pipeline().addlast(new protobufencoder()); // pipeline管理channel中的handler // 在channel队列中添加一个handler来处理业务 ch.pipeline().addlast("serverhandler", serverhandler);}});//....}在发送端的 pipeline 的最前面加上这个分割器,代码也是类似的, 这里不再赘述大家可以在文末源码查看
▌为什么拆包器要加在pipeline 的最前面?
这一点,需要从packagespliter 的根源讲起
下面是自定义分割器 packagespliter 的继承关系图
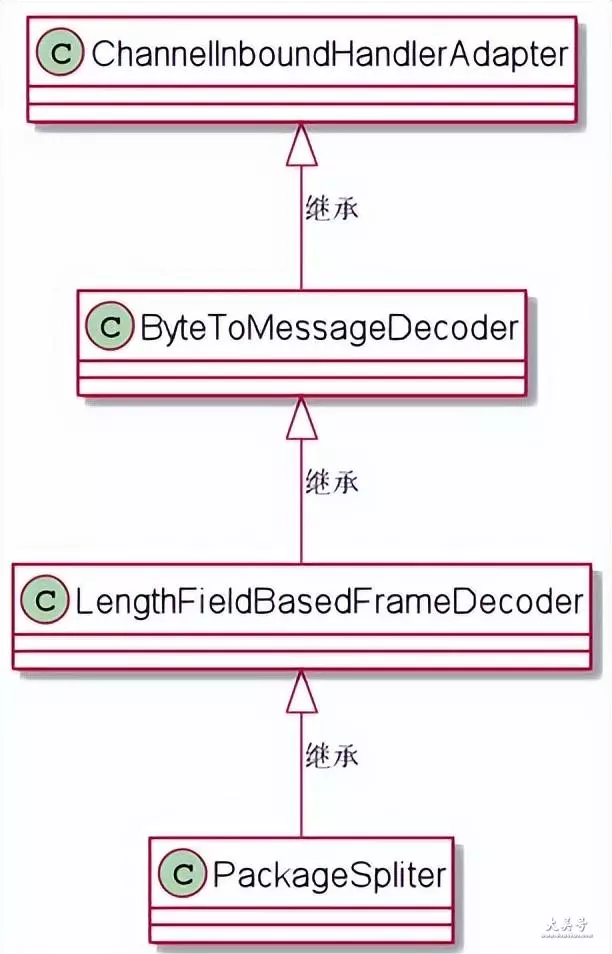
由此可见,分割器 packagespliter 继承了
channelinboundhandleradapter
本质上,它是一个入站处理器
在 关于netty的入站处理流程一文 pipeline inbound 中, 我们已经知道,netty的入站处理的顺序,是从pipelin 流水线的前面到后面
由于在入站过程中,解码器 protobufdecoder 进行应用层 protobuf 的数据包的解码,而在此之前,必须完成应用包的正确分割
所以, 分割器 packagespliter 必须处于入站流水线处理的第一站,放在最前面
题外话, packagespliter 分割器 和 protobufencoder 编码器 是否有关系呢?
从流水线处理的角度来说,是没有次序关系的
packagespliter 是入站处理器 在入站流程中用到
protobufencoder 是出站处理器,在出站流程中用到
特别提示一下: 发送端不存在粘包和半包问题这是接收端的事情
总之,在出站和入站处理流程上,分割器 packagespliter 和 编码器protobufencoder , 没有半毛钱关系的
▌写在最后:
至此为止,终于完成了 java 聊天程序实战的一些基础开发工作
包括了协议的编码解码包括了粘包和半包的拆包处理
大家好,我是大吴号,基本上可以开始 聊天器的正式设计和开发的详细讲解了
本文的源码工程:netty 粘包/半包原理与拆包实战 源码(
- 本实例是《netty 粘包/半包原理与拆包实战》 一文的源代码工程
▌技术自由的实现路径 pdf获取:
▌实现你的架构自由:
- 《吃透8图1模板,人人可以做架构》pdf
- 《10wqps评论中台,如何架构?b站是这么做的!》pdf
- 《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》pdf
- 《峰值21wqps、亿级dau,小游戏《羊了个羊》是怎么架构的?》pdf
- 《100亿级订单怎么调度,来一个大厂的极品方案》pdf
- 《2个大厂 100亿级 超大流量 红包 架构方案》pdf
… 更多架构文章,正在添加中
▌实现你的 响应式 自由:
- 《响应式圣经:10w字,实现spring响应式编程自由》pdf
- 这是老版本 《flux、mono、reactor 实战(史上最全)》pdf
▌实现你的 spring cloud 自由:
- 《spring cloud alibaba 学习圣经》 pdf
- 《分库分表 sharding-jdbc 底层原理、核心实战(史上最全)》pdf
- 《一文搞定:springboot、slf4j、log4j、logback、netty之间混乱关系(史上最全)》pdf
▌实现你的 linux 自由:
- 《linux命令大全:2w多字,一次实现linux自由》pdf
▌实现你的 网络 自由:
- 《tcp协议详解 (史上最全)》pdf
- 《网络三张表:arp表, mac表, 路由表,实现你的网络自由!》pdf
▌实现你的 分布式锁 自由:
- 《redis分布式锁(图解 - 秒懂 - 史上最全)》pdf
- 《zookeeper 分布式锁 - 图解 - 秒懂》pdf
▌实现你的 王者组件 自由:
- 《队列之王: disruptor 原理、架构、源码 一文穿透》pdf
- 《缓存之王:caffeine 源码、架构、原理(史上最全,10w字 超级长文)》pdf
- 《缓存之王:caffeine 的使用(史上最全)》pdf
▌实现你的 面试题 自由:
4000页《尼恩java面试宝典》pdf 40个专题
....
注:以上尼恩 架构笔记、面试题 的pdf文件,请到《技术自由圈》公众号获取
还需要啥自由,可以告诉尼恩 尼恩帮你实现.......
相关文章
-

名牌包包女士品牌排行榜
每个品牌都有一些自己的经久不衰的包款,这些包包就被我们称为经典款,爱马仕:kelly ,brikin ,contance爱马仕最保值的就是kelly和brikin ,他家冷门款较少,但是从保值率来看,猪鼻子,lindy 和花园包相对于来说保值率偏低,但是和其他品牌相比保值率已经非常nice香奈儿:金球,cf,2.55,leboy
2023-10-09 阅读 (117) -

ck包包是什么档次的品牌(keith是什么牌子)
charles keith通常在国内我们也叫它小ck,这个品牌来自于新加坡,性价比不错的品牌,销售的产品包括鞋子、包包、配饰等,下面我们就一起来看看charles keith是什么档次的牌子。小ck是什么牌子charles keith,由charles wong和keith wong兄弟于1996年创立的时尚公司,总部位于新加坡。
2023-10-13 阅读 (96) -

名牌包包回收平台(为何不把名牌包包换成现金)
你还在为家里有闲置奢侈品包包找不到回收平台而烦恼吗?这些年奢侈品回收app或者平台像雨后春笋一般遍布全网络,随便搜个关键词就出来很多app或平台,不知道哪个平台靠谱?不知道如何选择奢侈品回收平台?成了广大网友最头疼的事情,今天小编就跟大家介绍几个不错的闲置奢侈品包包回收平台,先了解在行动!闲置奢侈品回收平台有哪些?
2023-09-26 阅读 (112) -

包包脱皮了还可以补救吗(真皮包掉皮了怎么补救)
真皮包掉皮了怎么补救方法一:首先清理干净皮包,然在掉皮的地方涂上鸡蛋清,等鸡蛋清干了以后,涂一层与包包颜色相同的鞋油,然后放置阴凉处晾干就可以了,最后可以再涂上一层増亮油。方法二:使用和包包同颜色的蜡笔,然后再掉皮的位置进行轻轻擦拭,直到掩盖掉皮的位置即可。方法三:使用同颜色的指甲油来涂抹,指甲油最好选择防水不易掉的,这样能够暂时补皮包掉皮的位置。
2023-10-25 阅读 (392) -

chloe包包质量怎么样(Chloe 包包质量究竟如何)
chloe包包属于什么档次?今天,wed114结婚网小编为大家带来chloe小猪包真假辨别。在日常生活中,很多人特别喜欢chloe包包。不是很清楚chloe的档次,其实chloe蔻依应该算是一线的牌子。在日常生活中,很多人特别喜欢chloe包包。不是很清楚chloe的档次,其实chloe蔻依应该算是一线的牌子。
2023-09-11 阅读 (169) -

香奈儿走秀款包包圆圈图片(香奈儿2019年春夏包款合辑)
冬天想必是小仙女们最讨厌的季节啦!一来穿着臃肿笨重不够灵活,二来不能随心所欲背自己最爱的包包。不过诗人雪莱说过:冬天已经来了,春天还会远吗?面对即将来临的春天你是否准备好搭配的包包了呢?小编整理了chanel2019春夏的包款不如看看有没有你喜欢的款式吧~boy chanel香奈儿推出的新款boy在原款基础上改变了形状
2023-11-13 阅读 (118) -

杜嘉班纳包包价格(杜嘉班纳包包价格几何)
杜嘉班纳的包包是很多女生都买过的款式,非常好看,而且他家的包包质量也是很不错的,对得起这么高的价格。下面小编给大家讲讲杜嘉班纳包包专柜价格是多少?这款万元包包一定要买!杜嘉班纳包包专柜价格杜嘉班纳的包包专柜价格一般都是在一万元左右的,少数稀有皮的包包价格会比较高一些,和其他奢侈品牌的价位差不多,有喜欢的朋友赶紧买吧,不要等断货了再后悔。
2023-09-22 阅读 (99) -

牛皮包包品牌排行榜前十名
定居法国的英国女演员简·柏金(jane birkin)在巴黎寓所逝世,享年76岁。而出身于英国贵族家庭的jane birkin以白t恤、牛仔裤和菜篮子的经典造型闻名,还是爱马仕铂金包的灵感来源,她也被誉为时尚界的icon。爱马仕所设计的铂金包(hermés birkin bag)便是在1984年为简·柏金所设计的。
2023-09-17 阅读 (107) -

ysl包包价位多少钱一个(想要一款性感的 YSL 包包)
ysl圣罗兰包包价格多少钱?圣罗兰,来自法国著名的奢侈品牌,在国际上哪是赫赫有名的牌子货哦`特别是它家的包包很有名,既高档又有品味,不过价格也不菲。圣罗兰包包一般多少钱,圣罗兰这种大牌包包价格不用猜肯定不低,那么圣罗兰包包一般多少钱呢?据小编的了解它们家包包的价位贵则的几万,中等价位的一万多,最便宜的也要几千呢。
2023-10-11 阅读 (109) -

小小疯直播间包包是真的吗(直播带货哪些坑)
疫情推动直播购物的爆发式发展,直播带货悄然成为全民讨论的话题。为掌握直播带货的真实情况,今年双十一期间,浙江省消保委对淘宝、拼多多、京东、快手、抖音五个平台双十一直播带货进行了消费体察。总体情况:近四成商品检测不符合国家标准,体察发现较多问题。本次消费体察选择了淘宝7位主播、拼多多4位主播、京东2位主播、快手2位主播,抖音2位主播,包括网络人气排名前十位的李佳琦、薇娅、罗永浩、雪梨、烈儿宝贝、timor小小疯等知名主播。
2023-09-11 阅读 (130)
热门资讯
-
 2023-10-09 阅读 (3269)
2023-10-09 阅读 (3269) -
 2023-10-28 阅读 (2090)
2023-10-28 阅读 (2090) -
 2023-11-04 阅读 (1320)
2023-11-04 阅读 (1320) -
 2023-11-23 阅读 (953)
2023-11-23 阅读 (953) -
 2023-09-12 阅读 (685)
2023-09-12 阅读 (685)
最新资讯
-
 2023-11-27 阅读 (159)
2023-11-27 阅读 (159) -
 2023-11-27 阅读 (187)
2023-11-27 阅读 (187) -
 2023-11-27 阅读 (163)
2023-11-27 阅读 (163) -
 2023-11-26 阅读 (158)
2023-11-26 阅读 (158) -
 2023-11-26 阅读 (151)
2023-11-26 阅读 (151)